Replication
Explore this Page
- About Replication
- Benefits of Replication
- Replication Transfer Priority
- Replication Test Mode
- Replication Buffer
About Replication
Replication is the process of copying the data from a "source" virtual disk on one DataCore Server to a "destination" virtual disk on another DataCore Server. The destination virtual disk becomes a usable copy of the source virtual disk. Replication is achieved through asynchronous mirroring of the data.
A remote replication is the most usual application of this feature; meaning that the source is on a server in the local server group and the destination is on a server in a remote server group that is "partnered with the local group. One local group can also be partnered with multiple remote groups. Virtual disks can also be replicated locally from one server to another in the same local server group.
When replicating within the same server group, the port to be used for transmission of replication data between DataCore Servers cannot be specified. As such, data will be sent via the IP address which resolves from the replication server host name (the default DNS name resolution) and this IP may be used for communications other than replication traffic.
Each source virtual disk may only be replicated to one destination virtual disk. In other words, the same source virtual disk cannot be simultaneously replicated to more than one destination. A virtual disk can only be a member of one replication.
Replication is available in two types: Unidirectional and Bidirectional.
- Unidirectional replication allows data to be transmitted in one direction; from a virtual disk on a local DataCore Server (source) to a virtual disk on another DataCore Server (destination) and the direction cannot be reversed.
- Bidirectional replication (Advanced site recovery) allows data to be transmitted in two directions; from a virtual disk on a local DataCore Server (source) to a virtual disk on another DataCore Server (destination) and the direction can be reversed. In this case, the source and destination roles are switched. The original source becomes the new destination, and the original destination becomes the new source. An Advanced Site Recovery license (ASR) is required on both source and destination.
Replication was known as Asynchronous IP Mirroring (AIM) in earlier software versions.
Benefits of Replication
Virtual disk replication is beneficial in environments where synchronous mirroring is not a viable solution due to distance. This is because during the synchronous mirroring process, I/O write acknowledgements are not returned to the requesting host until the data is received by both DataCore Servers responsible for maintaining the mirrored virtual disks. Over long distances, the latency involved may directly and negatively impact performance.
With asynchronous mirroring, it is understood that the throughput between the sites is limited, and therefore, I/O writes to the source virtual disk are acknowledged immediately. Updating the data changes on the destination virtual disk is made as soon as possible, but does lag behind.
Replication provides capabilities that cannot be accomplished with a synchronous mirroring process:
- Off-site data backup and archiving over long distances.
- Emergency site failover for disaster recovery in the event of natural disaster, fire, and so on. (Bidirectional replication allows for site
- Controlled site swaps for situations; such as site maintenance, scheduled power cut-off, construction activity, and threat of a natural disaster. (Bidirectional replication allows for active sites to be swapped back when desired.)
The Process
Virtual disk replication occurs over TCP/IP connection via a proprietary transfer protocol
When a replication is created, the source and destination virtual disks are synchronized through initialization. Initialization is the process of creating a "baseline" image on the destination virtual disk. Existing data on the destination is overwritten, making the destination an identical copy of the source.
Initialization can be performed online or offline:
- Online initialization is an automatic process, but can require a significant amount of time – perhaps several days – to complete. Before the initialization process begins, source and destination virtual disks are checked for consistency. Data on the source is compared to data on the destination. Data transfers are kept to a minimum during initialization by only transferring data that does not already exist on the destination. When the destination disk is newly created and contains no data, a full initialization will occur. Should a problem occur during this process that requires initialization to restart, the data that already exists on the destination will not have to be transferred again. The time required to complete initialization will vary depending on the amount of data and data transfer rates. Online initialization is a good option if the source virtual disk has a small amount of data, or if the destination contains some of the same data that is on the source.
- Offline initialization is a manual process, but can save a significant amount of time. Offline initialization could be a good option when the source virtual disk has a large amount of data, as well as limited data transfer capacity. In this process, the source virtual disk data is automatically copied to a pre-existing folder location (removable drive, network location or local folder) using the Virtual Disk Details page>Replication tab for the source virtual disk. When all data has been copied to the offline replication buffer, prepare the data to be transported and deliver the data to the destination using a shipping or courier service. When the data has arrived at the destination, copy the data to the offline replication buffer on the destination. The data will be automatically copied from the offline buffer folder to the destination virtual disk using the Virtual Disk Details page>Replication tab for the destination virtual disk. Since all source data is simply copied to the destination, the source and destination virtual disks are not checked for consistency or compared as they are in the online initialization process.
Use a new, unused virtual disk for the destination. See Offline Initialization for details of this process.
After the replication is created, the I/O stream from the host is actively monitored for data changes. Every data change is collected, journalized, and stored in a dedicated buffer location. The data changes are transferred to the destination virtual disk as soon as possible. Data changes will continue to be transferred while the source and destination virtual disks are in a replication configuration.
When a replication is created, the source virtual disk has a status of "active" and is referred to as the "active" virtual disk because from the viewpoint of the host, the paths between the source virtual disk and the host are active. At the same time, the destination virtual disk has a status of "standby" is referred to as the "standby" virtual disk because any paths between the destination virtual disk and the host are disabled. For a complete list of replication states, see Replication Status.
Replication Transfer Priority
Replication transfer priority ensures that replication traffic is prioritized according to the replication priority setting in the storage profile assigned to a virtual disk Replication priority levels from highest priority to lowest priority are Critical, High, Regular (default setting), and Low.
Replication traffic of virtual disks with higher replication priority settings are given more available throughput to transfer data than virtual disks with lower priority settings.
All active replications to a destination server share one replication transfer path. Each replication priority level is assigned a quota of the total throughput of that transfer path. Virtual disks with a low priority will be afforded the smallest quota of the transfer path, while virtual disks with a critical priority will be afforded the largest quota of the transfer path. For example, assume there are three virtual disks with different replication transfer priorities: one critical, one high, and one regular. The critical virtual disk consumes 50% of the available throughput, the high virtual disk consumes 33% and the regular virtual disk consumes 17%.
Transfers within a priority queue are cycled in round-robin fashion so that if numerous replications exist with the same priority, data transfers are performed equally. If replications do not exist for all priorities, other replications will share the remaining throughput of the transfer channel based on the replication priority priorities.
- Replication transfer priority applies to the sender of the data or "Active" replication side only.
- Changes to the replication priority in the storage profile of a virtual disk have an immediate effect on data transfers.
Replication Test Mode
Test mode allows for a "trial run" of the process of reversing the replication direction. This is achieved by temporarily activating the standby virtual disk. Test mode is performed per virtual disk from the standby side of a replication. While in test mode, the standby virtual disk can be tested to ensure that paths are correctly configured and hosts on the standby side will have read/write access to the virtual disk. Data changes made to the standby virtual disk while in test mode are temporary and will be discarded after test mode is exited.
Replication traffic to the active virtual disk can continue while the standby virtual disk is in test mode.
For more information, see Replication Operations.
Reversing Replication Direction for Failover/Failback - Advanced Site Recovery
Advanced site recovery (ASR) allows for bidirectional replication and requires a replication license on the source and destination.
The replication direction can be reversed as required. When a controlled or emergency failover is necessary at the production (source) site, the roles of the source (active) and destination (standby) virtual disks can be swapped. When a failover is required, the replicated virtual disks at the failover site can be activated and made accessible to a host at the failover site. Data changes made by the host at the failover site will be added to the replication buffer created on the DataCore Server at the failover site.
When the production site is functional again, the failback process can begin. The virtual disks at the production side can be activated again. Data changes in the replication buffer at the failover site are transferred to the production site.
The following diagram depicts the recommended failover/failback scenario; the recommended scenario can be used for controlled and emergency failover/failback:
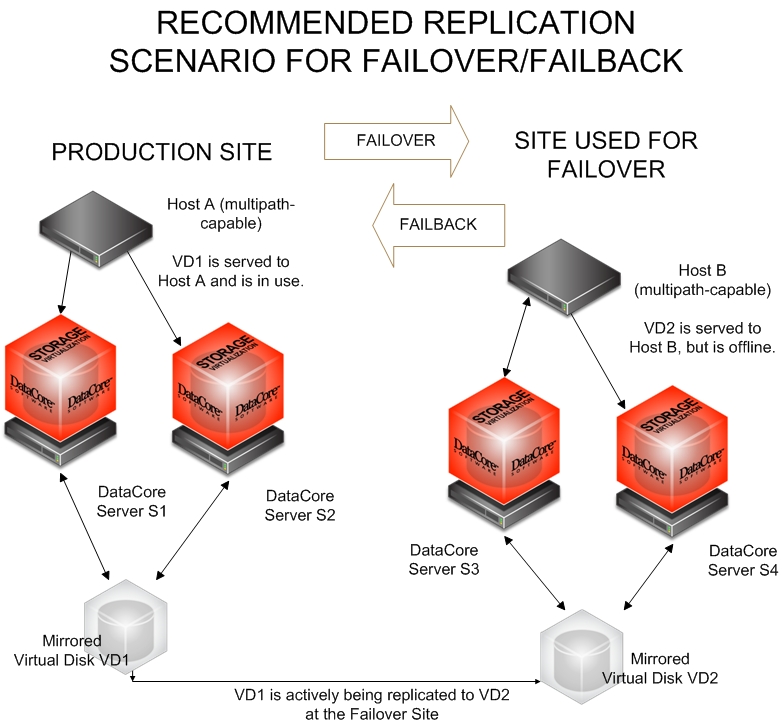
Initial set-up:
The production site and failover site are connected through a WAN link (VPN). The production virtual disk VD1 (active mode) is served to Host A and put to use. Data changes are being replicated to virtual disk VD2 (standby mode) at the failover site. VD2 is served to Host B (local to the failover site), but remains off-line until needed.
When a failover (controlled or emergency) is required:
The replication virtual disk VD2 is activated (goes from standby to active mode) at the failover site and the production virtual disk VD1 is de-activated (goes from active to standby mode).
VD2 at the failover site is put online to Host B and put into use. Data changes made by Host B to VD2 are added to the replication buffer on DataCore ServerS3.
When the production site is functional again and failback can occur:
VD1 at the production site can be activated again and put online to Host A.
VD2 is de-activated at the failover site and taken offline. Data changes that were made at the failover site are transferred from the replication buffer on DataCore Server S3 to DataCore Server S1 and destaged to VD1 at the production site.
Controlled Failover/Failback
In a controlled failover, the replication process eventually transfers all the pending files in the replication buffer to guarantee that both virtual disks are in a known, stable state.
Both virtual disks go through transitional states before the role swap is complete. The source virtual disk goes from Active to Deactivating state and blocks data transfers until all replication file transfers have completed on the destination virtual disk. The destination virtual disk goes from Standby to Activating state.
When both virtual disks are identical, the role swap is completed; the destination virtual disk goes into Active state and becomes the new source, and the old source goes into Standby state and becomes the new destination.
The newly activated virtual disk is served to a host at the failover site and put into use. Data changes made by the host at the failover site are added to the replication buffer on the DataCore Server at the failover site until the production site is functional again.
To failback to the production side, the virtual disks at the production site are activated again.
Emergency Failover/Failback
If the DataCore Server at the production site is unavailable, operations will be performed from the destination server at the failover site. The destination virtual disk is currently in Standby state. The replication configuration is split (removed), but the virtual disk remains and is made available to the host and put in use at the failover site.
When the production site is functional again, the replication configuration can be re-established from the failover site to the production site and allowed to initialize (synchronize). After the virtual disks are initialized, the virtual disks at the production site can be activated again.
For detailed failover/failback instructions, see Replication Operations.
Replication Operations
Replication operations can be performed from the Replication tab on the Virtual Disk Details page or from the panels. The Replication tab also provides specific information for the replication such as status, buffer size, time lag and transfer rate in order to monitor replications. See Virtual Disk Details and List for more information.
See Replication Operations for more information and instructions on performing replication operations. Replication operations can also be performed on virtual disk groups, see Virtual Disk Groups for more information.
Replication Checkpoints
A type of marker, called a checkpoint, can be used as triggers or actions for configured tasks, or to update existing snapshots on the destination server. Checkpoints are marked (inserted) in the data stream from the source server and transmitted to the destination server. When the checkpoint is received on the destination server, the actions are performed.
Since the checkpoint is a marker in a data transmission and latency does occur, the action will be delayed in time.
One possible application would be to mark a checkpoint when you are confident that the source virtual disk is in a consistent state and define the action to update a snapshot on the destination.
See Replication Operations for instructions.
Replication Buffer
The replication buffer is used to store data changes which have occurred on the source virtual disk and are waiting to be transferred to the destination server. The buffer should be created on any replication server which will be transferring data changes. If the replication type is bidirectional, then both servers will need buffers.
When replications are created, unique folders are created in the replication buffer for each virtual disk that is being replicated. As data changes are made on the virtual disk, sets of files (with block-level writes, timestamp, and sequence information) will accumulate in the buffer until they are transferred to the destination.
When files are received at the destination, they are de-staged in-memory and the contents are written on the destination virtual disk. Replication files remain in the buffer on the source server until they are successfully destaged at the destination.
Also see System Health Thresholds to set a an available space threshold for the replication buffer.
The location and size of the buffer will determine the function and speed with which the replication process can perform data transfers. Creating a replication buffer using the recommended guidelines is very important. The performance of the buffer is critical to the correct functioning of replications. Refer to the Best Practices Guide (FAQ 1348) on the DataCore Technical Support Portal for the recommended guidelines. If necessary, the buffer can be recreated accordingly. See Replication Operations for instructions on changing the buffer location.
Learn More