In this topic:
DataCore Deduplication Console
Setting the deduplication schedule
Increasing/decreasing deduplication pool size
Moving storage sources between pools
Deduplication is a technique for reducing allocated storage space by eliminating duplicate blocks of repeating data. In the process, redundant copies of the block are identified and a single copy is maintained. Redundant copies of blocks in multiple locations are replaced by a reference to the single copy which is then compressed. Deduplication also de-allocates space during the process. During file access the correct blocks are transparently assembled and is not evident at the file system level.
The data deduplication technology employed is post-processing deduplication. In post-processing deduplication, data is written to the disk and then optimized (deduplicated) on the disk. Post-processing deduplication runs in the background at low priority and has minimal impact on application I/O.
DataCore Software has developed a tool to create deduplication pools in SANsymphony software that leverage the proven capabilities of the Data Deduplication feature. Virtual disks created from these pools will be deduplicated on a schedule configured automatically by the tool. DataCore Deduplication extends the benefits of deduplication beyond the Windows operating system to any file system type while providing the advanced data services of SANsymphony software. The deduplication pool is created from an existing SANsymphony disk pool, referred to as the "storage source pool".
The Deduplication tool runs independently from the DataCore Management Console. The tool can be run locally on one server in a group or from a remote management console. The DataCore Deduplication Console is the user interface for the tool and can be used to create and manage deduplication pools on all servers in the server group.
![]() The Deduplication
tool requires SANsymphony
10.0 PSP 2 or later and Windows Server 2012 R2 operating system or later*
with the Data Deduplication role enabled under File and Storage Services.
(Refer to Microsoft documentation for more information about roles.)
The Deduplication
tool requires SANsymphony
10.0 PSP 2 or later and Windows Server 2012 R2 operating system or later*
with the Data Deduplication role enabled under File and Storage Services.
(Refer to Microsoft documentation for more information about roles.)
*Provided that the operating system version is supported by this software.
Data deduplication offers benefits such as lower storage space requirements and more efficient disk space use. Deduplication can optimize storage and reduce the amount of disk space consumed—when applied to the right data. Deduplication savings will vary widely based on the data type.
Generally, good candidates for deduplication are files that have plenty of duplication, are accessed less frequently, and have relatively static content. Poor candidates are files that change often and are constantly accessed by users or applications.
Good candidates for deduplication:
o General file shares: for example, group content publication and sharing, user home folders, and folder redirection/off-line files
o Software deployment shares: for example, software binaries, images, and updates
o Virtualization depot or provisioning library: for example, templates for virtual machines and virtual desktops, as well as virtual hard disk (VHD) file storage for provisioning to hypervisors
o Database backup volumes: for example, SQL Server and Exchange Server backup volumes
Candidates that should be evaluated based on content:
o Line-of-business servers
o Static content providers
o Web servers
Deduplication is not recommended for:
o Hypervisors (other than virtual hard disks and machine templates)
o Servers running Windows Server Update Services (WSUS), also known as Software Update Services (SUS)
o Servers running live databases: for example, Exchange Server or SQL Servers
o Virtual desktop instances
![]() Deduplication is not
supported for files that are open and
constantly changing for extended periods of time or have high I/O requirements.
Deduplication is not
supported for files that are open and
constantly changing for extended periods of time or have high I/O requirements.
Deduplication is not supported and has not been tested for combined use with the following software features:
o Virtual disks with the Sequential Storage feature enabled
o Virtual disks with Continuous Data Protection (CDP) enabled
o Virtual disks using the Snapshot or Replication features
o Disk pools of type Shared Multi-port Array (SMPA)
o Disk pools with Automated Storage Tiering feature enabled
o DataCore VDI Services, which is a tool that uses both DataCore Cmdlets and Microsoft PowerShell Cmdlets to create and maintain Hyper-V virtual desktop instances (VDIs). These VDIs are differential VDIs based off of a source image VDI. Using differential VHDX files for the VDIs result in VDIs that do not duplicate the information on the source image VDI making data deduplication unnecessary.
Scenario |
Data types |
Typical Space Savings |
User documents |
documents, photos, music, videos |
30-50%* |
Deployment shares |
software binaries, cab files, symbols files |
70-80%* |
Virtualization libraries |
virtual hard disk files |
80-95%* |
General file share |
file shares with all of the above data types |
50-60%* |
*Savings as reported by Microsoft. Results will vary by data type, mix, and file size. Microsoft provides a DDPEval tool to evaluate savings for Microsoft systems. For more information, refer to Microsoft documentation.
![]() DataCore Software can not guarantee
your results will match those of our examples or estimated savings.
DataCore Software can not guarantee
your results will match those of our examples or estimated savings.
o The maximum size of a deduplication pool is 64 TB.
o We recommend creating mirrored virtual disks using a storage source from two deduplication pools so that both sides of the mirror are deduplicated.
o Information in the DataCore Deduplication Console is refreshed when the console is opened, deduplication pools are created, or schedules are updated. However, it is not automatically refreshed in real time. Before performing any operation or reviewing the data in the console, click Refresh to manually update the information.
o Once the deduplication pool is created, do not add disks to the deduplication pool (except temporarily in the case of changing pool size, see Increasing or Decreasing Pool Size). Do not add pool mirrors.
o Creating a deduplication pool will create objects which will be visible in the DataCore Management Console and are identified as being "Internal Use" for the deduplication pool. Do not modify objects created and labeled as "Internal Use" or deduplication pools and deduplication tasks may fail.
o Do not change the script files and tasks that are automatically generated for each deduplication pool. (See Deduplication Tasks.)
o Creating a deduplication pool will create an "internal use only" volume in Disk Management with the same name as the pool. Do not rename the volume, or change or remove the drive letter in Disk Management. (The first available drive letter will be assigned to the volume. A drive letter must be available for use in order to create a deduplication pool.)
o Because the deduplication type is post-processing deduplication, making copies of data (such as adding a mirror to a single virtual disk or replacing a mirrored storage source) will consume the true amount of data and later be deduplicated.
o The performance class and write-aware auto-tiering settings in storage profiles for virtual disks created from a deduplication pool (which consists of one disk) will have no effect because there will only be one tier in a deduplication pool.
o Actual deduplication savings are realized in the SAUs of the storage source pool and the volume created from it. Only when an entire SAU is deduplicated will it be realized as free space in the storage source pool. The allocated storage space in the storage source pool will vary based on the SAU size of that pool and the number of contiguous blocks that are deduplicated. Some of the deduplicated space may be in SAUs that remain allocated to the volume but which are available for reuse with that volume only.
o Event messages from the Data Deduplication service are found in Computer Management> System Tools> Event Viewer> Applications and Services Logs> Microsoft> Windows> Deduplication.
o After a DataCore Server restarts or the server is shut down and restarted, it will take a brief moment for the deduplication pool status to go healthy (Running).
o After replacing a server or adding/changing physical disks on a DataCore Server with deduplication pools, ensure that the drive letters originally assigned to deduplication volumes created for each deduplication pool remain the same. (To identify the drive letters, see the Disk Pool Details page for each deduplication pool in the DataCore Management Console. The drive letter is contained in the description.)
o If a deduplication volume goes off-line in Disk Management, the deduplication pool created from it will be off-line. In this case, the volume must be remounted by running the task Internal Use - Mount Dedup VHD [#] for the correct volume. To identify the correct task to run for the volume, open Tasks in the DataCore Management Console. The task description contains the drive letter, deduplication pool name, and the DataCore Disk ID. (To check the status of volumes, see the DataCore Disk Details page for each DataCore Disk named Internal Use For [deduplication pool name] in DataCore Management Console, The status is displayed under the icon in the top left corner or under Disk Information in the Info tab. The Info tab also displays the Index number used in Disk Management.)
o Do not run disk
defragmentation software on deduplication volumes used to create deduplication
pools or volumes created from
deduplication pools.
![]() In Windows operating system, defragmentation is a maintenance mode
task that occurs automatically during optimization. Drives are optimized
automatically by default, so optimization must be disabled for volumes
involved in deduplication. Settings for scheduled optimization must be
changed by the administrator in the Windows Defragment and Optimize Drives
utility, so that volumes used in deduplication pools and volumes created
from deduplication pools are not selected for optimization. See
Microsoft documentation for more information.
In Windows operating system, defragmentation is a maintenance mode
task that occurs automatically during optimization. Drives are optimized
automatically by default, so optimization must be disabled for volumes
involved in deduplication. Settings for scheduled optimization must be
changed by the administrator in the Windows Defragment and Optimize Drives
utility, so that volumes used in deduplication pools and volumes created
from deduplication pools are not selected for optimization. See
Microsoft documentation for more information.
A pool is oversubscribed when the total size of all virtual disks created from the pool is greater than the size of the pool. Oversubscription simplifies capacity planning and maximizes capacity utilization. This is an acceptable practice and System Health safeguards such as available space threshold settings are provided for each pool so that administrators may increase pool size before running out of space.
On the other hand, administrators should be aware of potential issues that could result from drastically oversubscribing the storage source pool. Deduplication optimizes data capacity and therefore administrators may feel confident to oversubscribe by the amount of estimated savings or more. Note that deduplication will subscribe, but not necessarily allocate, 20% more space than the size specified for the deduplication pool.
![]() Certain events can cause a full mirror recovery which will cause
previously deduplicated data to "inflate" (or become undeduplicated)
to full size.
Certain events can cause a full mirror recovery which will cause
previously deduplicated data to "inflate" (or become undeduplicated)
to full size.
An auto-generated task is configured to run automatically when the available space on the storage source pool falls below the Attention threshold that is configured in the pool settings. When the task is triggered, the task will run a high priority deduplication on the affected deduplication pools. (See Deduplication Tasks for more information.) High priority deduplication will result in decreased performance while running due to the significant workload on the system. It is also theoretically possible that the high priority deduplication may not keep up with inflation if system resources are insufficient.
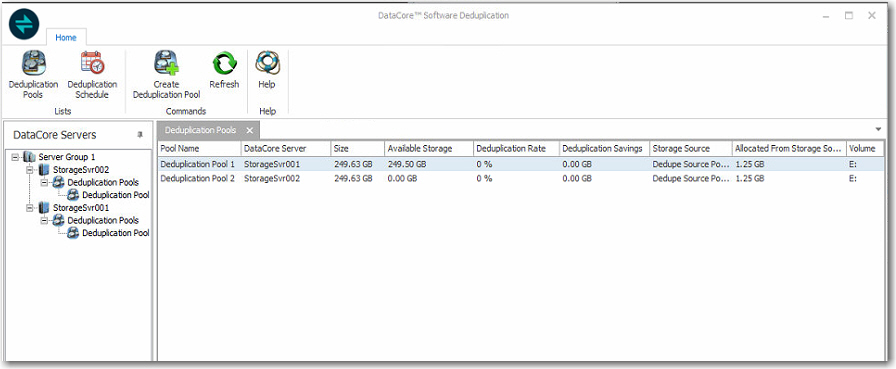
The DataCore Deduplication Console
presents information about DataCore Servers,
pools, disks, and savings in a single console so that administrators have
information needed to create and manage deduplication disk pools for a
server group. ![]()
The console includes:
o A Deduplication Pools List displayed in the right pane.
· Name, size, available storage, and the DataCore Server where the pool is located
· Deduplication rate and deduplication savings
· Storage source pool which was used to create the deduplication pool and the storage space allocated from it.
· Drive
letter of the deduplication volume created for Internal Use of the deduplication
pool.
![]() Information in the list is automatically refreshed when the console
is opened, deduplication pools are created, or schedules are updated.
Click Refresh
to manually update the information.
Information in the list is automatically refreshed when the console
is opened, deduplication pools are created, or schedules are updated.
Click Refresh
to manually update the information.
o A wizard that automates the creation of deduplication pools in this software.
o The ability to set the deduplication schedule for a DataCore Server.
o A panel that displays all deduplication pools in the server group at a glance. Pools are listed by DataCore Server. Click on servers or pools to open detail pages.
o Detail pages for Deduplication pools and DataCore Servers showing information pertinent to deduplication.
o A Refresh button to update information in the Deduplication Pool lists.
o A Help button that opens to the Deduplication topic in the online Help.
To open the console:
1 Open the Deduplication tool from the Apps menu under Apps menu>DataCore>DataCore Deduplication.
2 In the Connect to Server Group dialog box:
a Connect to the server where the deduplication pool will be created.
b Enter
the user name and password to login to the server. Explicit
(not default) credentials are required.
(If domain credentials are used, include the domain with the name for example:
DOMAIN\user name.)
c Click Connect to continue.
![]() Information about deduplication pools is gathered
for the server group and may take a moment to display.
Information about deduplication pools is gathered
for the server group and may take a moment to display.
Information pertaining to deduplication and the deduplication pools
is collected and displayed for each DataCore Server
in a DataCore Server Details page.
The deduplication schedule can also be set for the server in this page.
![]()
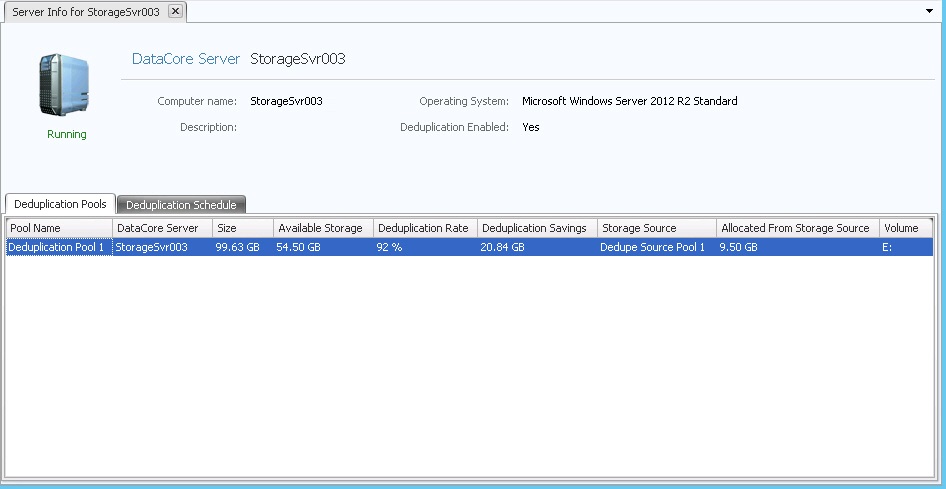
At the top of the page:
o The DataCore Server status is displayed at the top of the page under the server icon.
o The computer name, description, operating system is displayed.
o The page will show if the Data Deduplication role is enabled.
To open the details page:
In the DataCore Deduplication Console, click the server in the left panel to open the details page.
DataCore Server Details Tabs |
|
| Deduplication Pools | Displays deduplication pools created on the server and general information: size, available storage, deduplication rate and savings, storage source of the pool, amount of storage allocated from the storage source pool for the deduplication pool, and drive letter assigned to the volume created from the storage source pool. A deduplication pool without virtual disks created can be deleted from this list from the context menu. |
| Deduplication Schedule | Provides the current deduplication schedule settings for the server and enables changes to the current settings. See Setting the Deduplication Schedule. |
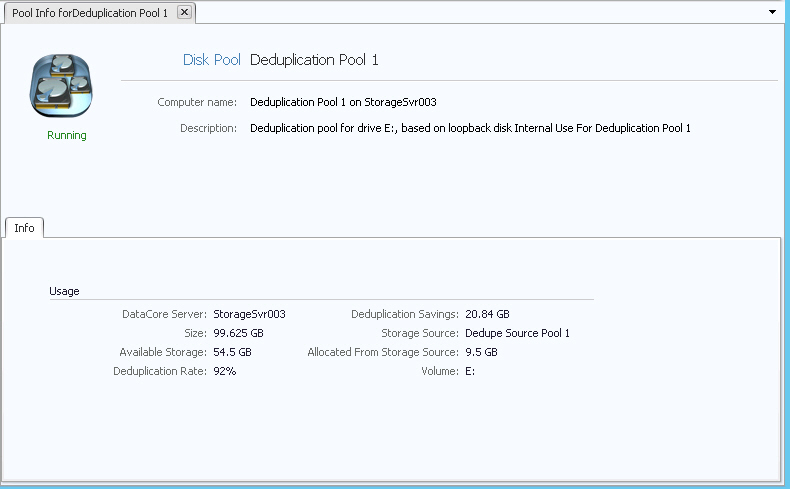
Information for each deduplication pool is collected and displayed in
a Disk Pool Details page.
![]()
At the top of the page:
o The deduplication pool status is displayed at the top of the page under the server icon. (All disk pool status applies to a deduplication pool except for Redundancy Failed.)
o The computer name and description is displayed. The description cannot be edited.
To open the details page:
In the DataCore Deduplication Console, click the deduplication pool in the left panel to open the details page.
The Info tab displays usage details such as server name, pool size, available storage, deduplication rate and savings, storage source of the pool, amount of storage allocated from the storage source for the deduplication pool, and drive letter assigned to the deduplication volume created from the storage source pool.
Deduplication pools can be created from an existing SANsymphony disk pool ("storage source pool") by running a wizard in the console. The storage source pool does not need to be dedicated, but can be used for other purposes. In addition to creating the pool, the wizard also creates tasks used to maintain the pool and sets a deduplication schedule that will run background optimization.
Deduplication pools are created with the same SAU size as the storage source pool.
To create a deduplication pool:
1 In the DataCore Deduplication Console, click Create Deduplication Pool in the ribbon to open the wizard.
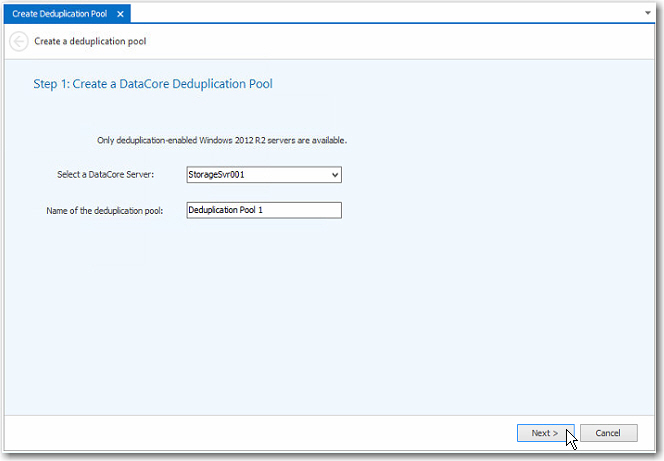
2 Step 1: Create a deduplication
pool: ![]()
a Select the DataCore Server on which the deduplication pool should be created.
b Enter the name of the deduplication pool to be created.
c Click Next to continue.
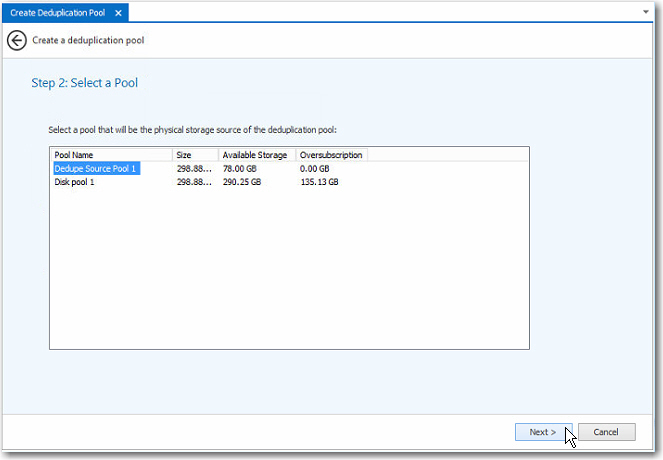
3 Step 2:
Select a Pool ![]()
a In the list, select the existing SANsymphony disk pool to be used as the storage source of the deduplication pool.
b Click Next to continue.
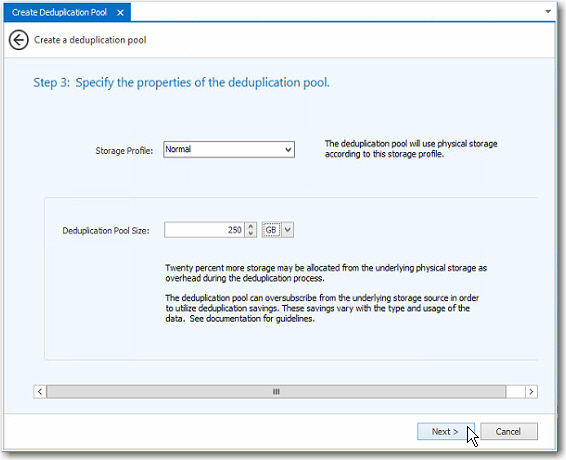
4 Step 3:
Specify the Properties of the Deduplication Pool ![]()
a Select the storage profile to use for the physical storage taken from the storage source pool. This underlying storage will be used to create the deduplication pool.
b Specify the size of the deduplication pool.
§ The size
of the deduplication pool can be oversubscribed in anticipation of estimated
savings to be realized in the deduplication process.
Note: Savings will vary considerably based on the type and usage of the
data.
§ Twenty percent more space than the size specified will be subscribed, but not necessarily allocated, from the storage source pool. For example, if the size of the deduplication pool is 100 GB, 120 GB will be subscribed from the storage source pool. This additional space is required to support the deduplication process.
· Click Next to continue.
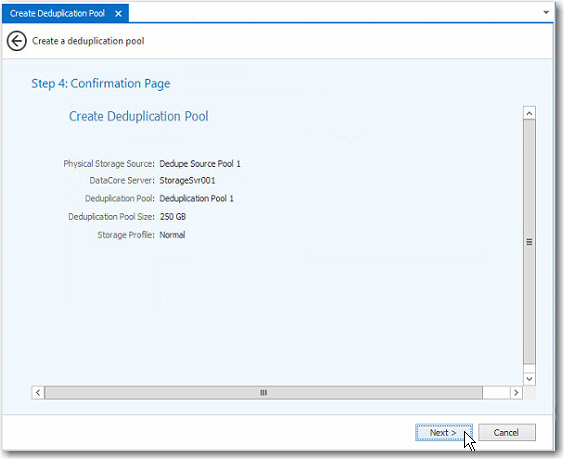
5 Step 4:
Confirmation Page ![]()
a Confirm your selections for the deduplication pool and click Next to continue.
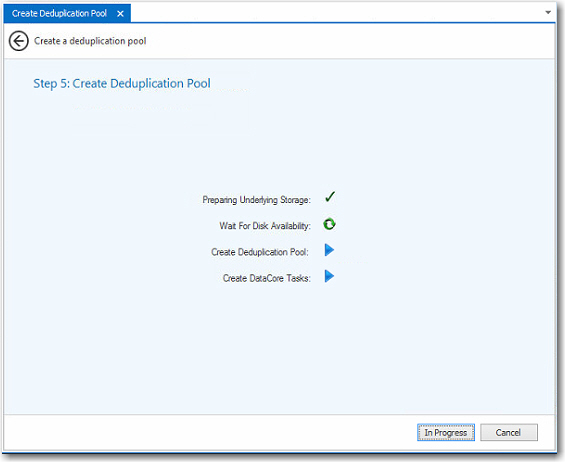
6 Click
Start to begin the process of
creating the deduplication pool. Creating the pool may take some time.
Progress is indicated on the wizard page. Green check marks represent
completed actions and a green circular arrow represents the current action
being performed. ![]()
7 When all tasks have been completed, click Finished to close the wizard.
8 During
pool creation, the operating system on the DataCore Server
where the pool was created will find a new disk which will generate a
message asking if you would like to format it. Click Cancel
on the message. ![]()
9 Disable scheduled optimization for the volume created as the source of the deduplication pool.
a Find the drive letter of the volume in Disk Management (the volume will have the same name as the deduplication pool) or in tasks (the task description will identify the pool and drive).
b Open the Windows Defragment and Optimize Drives utility. Change the settings for the scheduled optimization so the drive is not selected for optimization. See Microsoft documentation for more information.
Just as with any pool, the pool cannot be deleted if it is used as a storage source in virtual disks; all virtual disks created from the pool must be deleted. Deleting the deduplication pool from the DataCore Deduplication Console will also delete the associated "Internal Use" objects that were created to support it.
To delete a deduplication pool:
In the DataCore Deduplication Console>Deduplication
Pools List, right-click on the pool to delete and select Delete from the context menu.
Alternatively, the pool can be deleted the from the DataCore Server Details page>Deduplication
Pools tab in the tool.
Deduplication schedules can be set for background and throughput optimization in the console.
Deduplication is a processor and I/O intensive task and therefore best suited to run as a low-priority background task when the system is not busy with other processing. Data that has been written to the disk can be optimized post-processing on the disk at a convenient time during off hours.
When a deduplication pool is created, deduplication is automatically scheduled to run regularly as a background optimization, which runs deduplication at low priority and pauses when the system is busy. Deduplication can be set for both background and throughput optimization if necessary.
![]() The Set Deduplication
Schedule setting is a server setting and applies to all deduplication pools on a particular
server.
The Set Deduplication
Schedule setting is a server setting and applies to all deduplication pools on a particular
server.
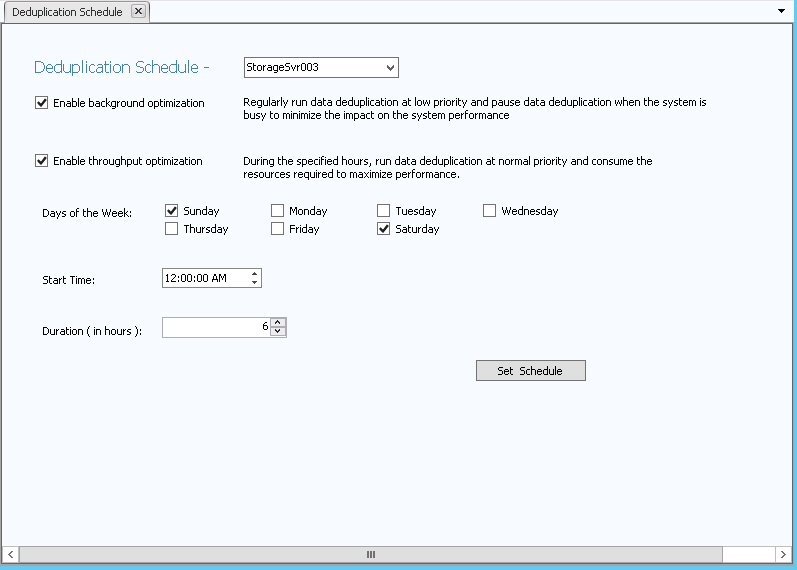
To set the deduplication schedule for a DataCore Server:
1 In the
DataCore Deduplication Console,
click Deduplication Schedule
in the ribbon and select the DataCore Server
from the list.
Alternatively, the Deduplication Schedule for a DataCore Server
can be opened from DataCore Server Details page>Deduplication
Schedule tab.
2 Select the optimization
type: ![]()
Either or both types may be selected.
a Background optimization will run deduplication at low priority whenever the system is not busy and pause whenever the system is busy.
b Throughput optimization will run
only during the hours specified and will run at normal priority.
![]() This mode will
consume whatever system resources are necessary to optimize duplicated
data.
This mode will
consume whatever system resources are necessary to optimize duplicated
data.
i In Days of the Week, select or clear the check boxes so that only the days when deduplication should run are selected.
ii In Start Time, enter the time when deduplication should begin.
iii In Duration, enter the number of hours that deduplication should run.
3 Click Set Schedule.
Deduplication pools consist of one disk which is added to the pool when it is created. There are two recommended methods of increasing or decreasing a deduplication pool.
![]() Adding disks to an existing deduplication
pool can result in a loss of deduplication savings and is not advised
as a permanent solution. (see Important
Notes).
Adding disks to an existing deduplication
pool can result in a loss of deduplication savings and is not advised
as a permanent solution. (see Important
Notes).
Method 1
![]() Before beginning, see Replacing/Moving
a Storage Source in a Virtual Disk for complete information about
the Move operation.
Before beginning, see Replacing/Moving
a Storage Source in a Virtual Disk for complete information about
the Move operation.
1 In the DataCore Deduplication Console, create a new deduplication pool of the desired size.
2 In the DataCore Management Console,
use the Move
operation to move the existing storage sources from the current pool to
the new pool.
The Move operation will move the
virtual disk storage sources created from the pool while maintaining high
availability during most of the process and only requires a log recovery.
The storage sources must be mirrored in order to use the Move operation.
Moving data can take several hours depending
on the amount of allocated SAUs and the amount of I/O from the host during
the operation.
![]() Do not
use the Replace operation to move the storage sources.
Do not
use the Replace operation to move the storage sources.
3 After the move is complete, delete the original deduplication pool.
Method 2
![]() Before beginning, see Removing
Physical Disks from Pools for complete information about the Remove from Disk Pool operation.
Before beginning, see Removing
Physical Disks from Pools for complete information about the Remove from Disk Pool operation.
1 In the DataCore Deduplication Console, create a new deduplication pool of the desired size.
2 In the DataCore Management Console, use the Remove from Disk Pool operation to remove the disk from the new deduplication pool. (The operation will only take a moment because virtual disk data has not been written to the disk.)
3 Add the new physical disk from the new deduplication pool to the original deduplication pool.
4 Use the Remove from Disk Pool
operation to remove the original disk from the original deduplication
pool.
The Remove from Disk Pool operation
will cause copy the allocated SAUs from the original disk to the new physical
disk. Copying data from the original
disk to the new disk can take a considerable amount of time.
Virtual disk storage sources created from a deduplication pool may be moved to another pool (deduplicated or non-deduplicated) on the same server. Storage sources from non-deduplicated pools may also be moved to deduplicated pools on the same server.
![]() Before beginning, see Replacing/Moving
a Storage Source in a Virtual Disk for complete information about
the Move operation.
Before beginning, see Replacing/Moving
a Storage Source in a Virtual Disk for complete information about
the Move operation.
To move storage sources:
1 In the DataCore Management Console, open the Virtual Disks List.
2 Select the virtual disks in the list and point to Move in the context menu and choose the DataCore Server from where the storage sources will be moved.
3 In the dialog box, select the pool on the same server where the storage sources will be moved.
4 Click Move to continue with the operation.
Two automated tasks are automatically configured for each deduplication pool that is created. The tasks assist in the creation and maintenance of deduplication pools.
![]() The script
files and tasks described in this section are required to create and maintain
the deduplication pool properly and should not be altered in any way.
The script
files and tasks described in this section are required to create and maintain
the deduplication pool properly and should not be altered in any way.
Tasks:
o Mount Dedup VHD
If the Deduplication Volume (VHD file) becomes unavailable for any reason,
such as after a DataCore Server
restart, the operating system will not automatically remount the Deduplication
Volume. When a monitor detects that the state of the Deduplication Volume
created from the storage source pool reaches the Healthy state, the PowerShell
script MountVHD.ps1 is invoked
to remount the volume.
o Run
Deduplication
Certain events can cause previously deduplicated data to "inflate"
to full size. This task runs a high
priority deduplication and prevents inflation so that the physical
storage used to create the deduplication pool is not exceeded. (See Oversubscription and Inflation.)
The task has a trigger configured to monitor the available
space threshold for the storage source pool. The task will be triggered
when the monitored available space on the storage source pool falls below
the Attention threshold (is greater than Healthy) as configured in the
pool settings. When this happens, the PowerShell script RunDeDupJob.ps1
is automatically invoked to quickly deduplicate the inflated data.
![]() A high priority task will consume all resources necessary to quickly
deduplicate the pool and creates a significant workload on the system.
A high priority task will consume all resources necessary to quickly
deduplicate the pool and creates a significant workload on the system.
Details for tasks (such as last start time and the last stop time) can be viewed from the Tasks tool in the DataCore Management Console.